2.9 Analyzing Departures from Linearity
6 min read•june 18, 2024
Avanish Gupta
Jed Quiaoit
AP Statistics 📊
265 resourcesSee Units
Sometimes, the least squares regression model may not be the best for representing a data set. We’re going to list some reasons why. While we briefly introduced them in section 2.4, we'll go into further detail here.
Influential Points
An influential point is a point that when added, significantly changes the regression model, whether by affecting the slope, y-intercept, or correlation. There are two types: outliers and high-leverage points, which are both shown in this graph. ⚒️
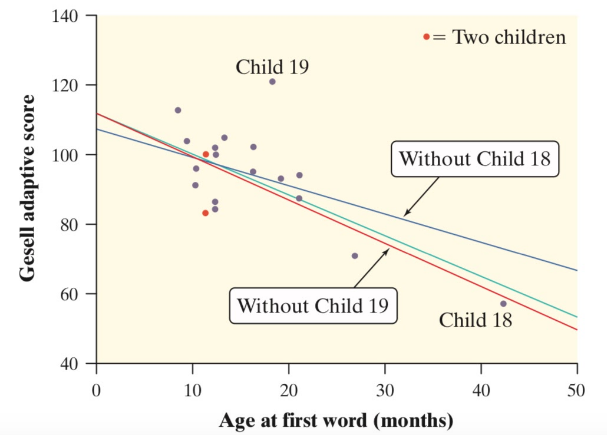
Courtesy of Starnes, Daren S. and Tabor, Josh. The Practice of Statistics—For the AP Exam, 5th Edition. Cengage Publishing.
Outliers
An outlier is a point in which the y-value is far away from the rest of the points, that is, it has a high-magnitude residual. These points heavily reduce the correlation of the scatterplot and can occasionally change the y-intercept of a regression line. Child 19 on the scatterplot above is an outlier. 😳
High-Leverage Points
A high-leverage point is a point in which the x-value is far away from the rest of the points. These points pull the regression line towards this point, and thus can significantly change the slope of the line. It can occasionally change the y-intercept of a regression line. Child 18 on the scatterplot above is a high-leverage point. 🎩
Overall, it's crucial to identify influential points in a regression model because they can have a large impact on the estimates of the model parameters and the overall fit of the model. If an influential point is an outlier, it may be appropriate to exclude it from the model because it may not be representative of the underlying pattern in the data. If an influential point is a high-leverage point, it may be worth considering whether the model is appropriate for the data or if a different model would be more suitable.
Transforming Data and Nonlinear Regression
Sometimes, a linear model is not a good fit for a set of data, and thus it is better to use a nonlinear model. The types that we have to know for this class are exponential and power regression models. (There is also polynomial regression, but that requires knowledge of linear algebra, which is beyond the scope of this course.) 💃
To use exponential and power regression models, it is usually necessary to transform the data to linearize it. This involves applying a function to the predictor and/or response variables in order to transform them into a form that is more suitable for linear regression. For example, the logarithmic transformation is often used to linearize exponential data, while the square root or logarithmic transformation is often used to linearize power data.
Don't worry, though! Most calculators have options to automatically calculate this for you.
Exponential Models
Exponential models have the form ŷ=ab^x, where a and b are constants and x is the explanatory variable. In order to fit an exponential model using linear regression, it is necessary to transform the data so that the relationship between the transformed response variable and the predictor variable is linear. 🚚
To do this, you can take the natural logarithm of both sides of the exponential model equation. This gives you ln(ŷ) = ln(a) + ln(b)x. The relationship between ln(ŷ) and x is now linear, so you can fit a linear regression model to the transformed data. The y-intercept of the model will be equal to ln(a), and the slope will be equal to ln(b).
This means that the relationship between ln(ŷ) and x is linear, so we find the LSRL of this transformed data with the y-intercept being a* and the slope being b*. To find a and b, we use:
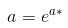
image courtesy of: codecogs.com
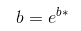
image courtesy of: codecogs.com
Power models have the form ŷ=ax^b. Like exponential models, we also take the natural logarithm of both sides, and with manipulation, we get ln(ŷ) = ln(a) + bln(x). This time, the relationship between ln(ŷ) and ln(x) is linear. With the LSRL of the transformer data again having y-intercept a* and slope b*, we have:
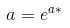
image courtesy of: codecogs.com
and b = b*.
How Can I Tell, Then?
When evaluating which transformation to use in an exponential or power regression model, it's important to consider both the residual plots of the transformed data and the R^2 value. We pick the right model by seeing whether the residuals are randomly scattered and not curved and also whether the R^2 is close to 1. 🔎
By the way, the R^2 is interpreted as the percent of variation in the response variable that can be explained by a power/exponential model relative to the explanatory variable, which is very similar to its linear counterpart. If the conditions above aren’t met, then there may be another model that may work that we haven’t learned or there are influential points skewing the data set, which is more likely!
To summarize, if our data appears to be an exponential model, we need to take the natural log (or any other base log) of our y coordinates. If our data appears to be a power model, such as a quadratic or cubic function, we need to take the log of both our x and y coordinates.
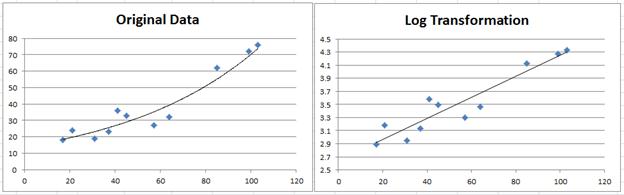
Source: Real Statistics
🎥 Watch: AP Stats - Exploring Two-Variable Data
Practice Problem
You are a statistician working for a company that manufactures and sells a certain type of light bulb. The company wants to understand how the price of the light bulbs affects the number of units sold. To do this, you collect data on the number of units sold and the price of the light bulbs for a sample of 50 different stores.
You begin by performing a linear regression on the data and find that the model has a poor fit, with a low R-squared value. You decide to try transforming the data by taking the natural logarithm of the number of units sold, and then performing a linear regression on the transformed data.
You find that the transformed data has a better fit, with a higher R-squared value. The equation of the transformed model is:
ln(units sold) = 0.5 * ln(price) + 2
You want to transform the model back to its original form so that you can make predictions in terms of the original variables. To do this, you can use the following formula:
units sold = e^(b * price^a), where a and b are constants.
Using the equation of the transformed model, find the values of a and b in the original model.
⭐ Hint: Remember that the natural logarithm of a number is the exponent to which the base e must be raised to get that number. For example, ln(2) = 0.69, because e^0.69 = 2.
Answer
First, we need to rewrite the equation of the transformed model in terms of the original variables. Since ln(units sold) is equal to 0.5 * ln(price) + 2, we can rewrite this equation as:
ln(units sold) = ln(price^0.5) + 2
Using the property of logarithms that ln(a^b) = b * ln(a), we can rewrite the equation as:
ln(units sold) = 0.5 * ln(price) + 2
Then, we can use the formula for the original model to find the values of a and b. Setting a equal to 0.5 and b equal to e^2, we get:
units sold = e^(2 * price^0.5)
Therefore, the values of a and b in the original model are a = 0.5 and b = e^2.
Browse Study Guides By Unit
👆Unit 1 – Exploring One-Variable Data
✌️Unit 2 – Exploring Two-Variable Data
🔎Unit 3 – Collecting Data
🎲Unit 4 – Probability, Random Variables, & Probability Distributions
📊Unit 5 – Sampling Distributions
⚖️Unit 6 – Proportions
😼Unit 7 – Means
✳️Unit 8 – Chi-Squares
📈Unit 9 – Slopes
✏️Frequently Asked Questions
📚Study Tools
🤔Exam Skills
Fiveable
Resources
© 2025 Fiveable Inc. All rights reserved.